In this series looking at features introduced by every version of Python 3, we take a look at some of the new features added in Python 3.13. In this article we look at the remaining changes to the standard library, comprising changes in CLI tools, concurrency, networking & IPC, Internet data handling, XML processing, IP address handling, development & debugging tools, and runtime and language tools.
This is the 36th of the 36 articles that currently make up the “Python 3 Releases” series.
")
In the previous post in this series we looked at half the changes in the standard library, and in this one I’m going to cover the rest and complete my review of the changes in Python 3.13.
We’ll kick off with a simple but useful change in the argparse module, the current recommended option in the standard library for handling command-line application option parsing, which now has a way to flag deprecated command-line options.
argparse¶Whenever you maintain an application for a period of time, there come points where you need to change its interfaces, whether they be APIs, UIs or command-line interfaces—that third option is the subject of this change in argparse. There’s now a deprecated parameter which you can pass to add_argument(), when adding command-line options to the parser, or add_parser(), when adding sub-parsers—this latter case is probably a bit niche for many readers, however1.
Unsurprisingly this new parameter defaults to False, but if you set deprecated=True then it’s a hint to your users that you plan to remove this option in the future. Whenever this option is used, a warning is printed to stderr that the option is deprecated. Here’s a simple example of its use.
| someapplication.py | |
|---|---|
1 2 3 4 5 6 7 8 | |
Below you can see the output from running this application. One detail that I did notice is that the help text isn’t modified in any way—I wondered if perhaps something like [DEPRECATED] might be added, but apparently if you want that then you need to do it yourself2.
$ ./someappliction.py --foo
someappliction.py: warning: option '--foo' is deprecated
$ ./someappliction.py --help
usage: someappliction.py [-h] [--foo]
options:
-h, --help show this help message and exit
--foo, -f specifies the metasyntactic variable to use
Next up are a change to subprocess to use posix_spawn() in more cases, and a new shutdown() method on queue.Queue objects.
subprocess¶On many Unix platforms, the subprocess module has two choices to execute child processes—one is to use its own implementation in C which calls fork() and exec() separately, and does a whole ton of additional housekeeping; the other is to just use the posix_spawn() call, which is a simpler interface specifically designed for this case.
To give you some idea of the complexity of the first option, at time of writing implementation of subprocess_fork_exec_impl(), and its helper do_fork_exec() call, come in at over 350 lines of C code. This isn’t too surprising—when you have to deal with the details of things like process groups and sessions, things get fiddly. But it illustrates the value of letting the OS authors do the job for you, providing it does what you need.
The main barrier to using posix_spawn() in the past has been that it didn’t implement the behaviour required for the close_fds option, which closes all of the parent’s open file descriptors in the child process, except stdin, stdout and stderr. This is the default behaviour unless you specify otherwise, and is generally a good idea unless you know what you’re doing.
As we saw in the previous article, however, posix_spawn() now has support for closing all file descriptors above a specified limit on many platforms. Where this support is present, therefore, the close_fds=True behaviour can be supported, and thus posix_spawn() can be used directly in many more cases.
This change has been made in Python 3.13, which should help to streamline spawning child processes slightly—that said, I doubt you’ll notice a great deal of difference at runtime unless you’re doing a lot of spawning child processes. Note also that there are still things which prevent posix_spawn() being used—using the cwd, pass_fds, start_new_session options are examples of this.
queue¶There’s also a change in queue.Queue to add a shutdown() method. This marks a queue as “shutting down” and after this point any calls to get() or put() on the queue will raise a new queue.ShutDown error. This also wakes them up as a byproduct. This is quite handy, because it means that you can write a thread that simply blocks on get() to retrieve work items without worrying about having to wake up periodically to see if you should shut the thread down if the application is terminating—instead you can just rely on the main thread to call shutdown() on all the Queue objects, any everyone will get woken up and get a ShutDown exception that they can handle to gracefully terminate.
There’s some fine details that are worth being aware of, however. Whilst put() on a shutdown Queue will always immediately return ShutDown (because you don’t want to add anything to a queue that’s shutting down), get() will only raise ShutDown once the queue is empty—until that point it’ll retrieve the remaining items. This is often what you want, to finish processing outstanding work before you terminate.
If you want to shutdown immediately regardless of what items are in the queue, you can pass immediate=True to shutdown(), and this causes get() to immediately raise ShutDown. Since join() calls wait until task_done() was called on every current item, if shutdown() is called with immediate=True then this also has the effect of calling task_done() for each pending item, in an effort to unblock anything that would otherwise it blocked in join() waiting for these to complete. Be aware, however, that any items which were removed from the queue before the call to shutdown() still need corresponding calls to task_done() or join() will continue to block.
Looking at networking and interprocess communication, we have a number of assorted changes to the asynio module, an mmap file that supports seek(), and changes to the ssl module’s default flags in the create_default_context() method. Let’s look at these in more detail.
asyncio¶There are a number of more or less unrelated changes to asyncio, which continues to be one of the modules that’s evolving the most in each release. There are a couple which seemed more interesting to me, so I’ve gone into a little detail, and then a handful more which I’ve just briefly outlined.
as_completed() iterator¶First up, an update to asyncio.as_completed(). This runs a series of awaitable objects and yields the results of them as they complete. Prior to Python 3.13, this returned just a plain iterator, which yielded coroutines which themselves would return the results:
>>> import asyncio, time
>>> async def delay(secs):
... await asyncio.sleep(secs)
... return secs
...
>>> async def parallel():
... start_time = time.time()
... one, two, three = (delay(i) for i in (1, 2, 3))
... for result_coroutine in asyncio.as_completed((one, two, three)):
... print(f"{time.time()-start_time:.2f}", "Got result...")
... result = await result_coroutine
... print(f"{time.time()-start_time:.2f}", "Result", result)
...
>>> asyncio.run(parallel())
0.00 Got result...
1.00 Result 1
1.00 Got result...
2.00 Result 2
2.00 Got result...
3.00 Result 3
In Python 3.13, however, the object that’s returned can also be used as an asynchronous iterator. The difference here is that, if the original awaitables are tasks or futures, then the awaitable itself is yielded. This can make context-sensitive behaviours easier by allowing direct comparisons with the coroutines. For awaitables which aren’t tasks or futures, new tasks are implicitly created for them as before.
Also compare the timestamps with the examples above, illustrating that the asynchronous iterator returned by as_completed() only yields when the underlying coroutine returns.
>>> async def parallel():
... start_time = time.time()
... one, two, three = (asyncio.create_task(delay(i)) for i in (1, 2, 3))
... async for result_coroutine in asyncio.as_completed((one, two, three)):
... print(f"{time.time()-start_time:.2f}",
... f"Got {"FIRST" if result_coroutine == one else "OTHER"} result")
... result = await result_coroutine
... print(f"{time.time()-start_time:.2f}", "Result", result)
...
>>> asyncio.run(parallel())
1.00 Got FIRST result
1.00 Result 1
2.00 Got OTHER result
2.00 Result 2
3.00 Got OTHER result
3.00 Result 3
Shutdown of an asyncio server has always been a little messy if you have long-running connections. You can call close() on the server object, but this doesn’t do anything about existing connections—it always waits for them to gracefully shut down. This may be fine if they’re short-lived, or if the higher-level protocol they’re running has a way to request disconnection, but sometimes you just want to disconnect everyone.
As of Python 3.13, the Server object now has a close_clients() method to do exactly this. I’m very far from an asyncio expert, but here’s a simple server I wrote which illustrates one way it can be used. It handles TCP connections, assuming it’ll receive UTF-8 text on them and just echoes back each line with a message. You can send \quit to terminate the connection if you want.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
The key point here is that shutdown_server() first calls close() to stop accepting new connections—but then it also calls the new close_clients() method to close any existing connections. This will call close() on the transports associated with those connections. When the StreamReader used by the connection handlers is closed, this immediately returns an empty string (same as if the connection is closed by the remote end) and this is handled gracefully. Any pending data should be flushed through before closing.
One thing that’s important to note here is that the order of calling close() on the server and then close_clients() is important—if you close existing clients first, then there’s a race condition where a new connection might arrive between that and the call to close() which prevents the new connection from being accepted.
Here’s the output of that script when terminated with SIGTERM whilst two connections are open:
Starting server pid=86977
New connection
New connection
Stopping new connections
Closing existing clients
Connection closed
Client terminated
Connection closed
Client terminated
Server terminating
It might be worth noting that any handlers which don’t immediately respond to the closing might get cancelled as your main task exits, if they await on anything which causes execution to return to the main loop early.
There is a wait_closed() async method which you might be tempted to use to force the main task to wait until everything is fully exited, but this only blocks until all connections are closed, not until their tasks themselves are terminated—since close_clients() calls close() on them all then this isn’t going to help. I confirmed this by adding await asyncio.sleep(5) at the end of handle_client(), and confirmed that the task was cancelled before it completed.
To try and find a way of doing this, should it be required, I played around and found an approrach that seemed to work—essentially just calling asyncio.wait() on all of the other tasks from the end of run_server().
to_wait = {task for task in asyncio.all_tasks()
if task != asyncio.current_task()}
await asyncio.wait(to_wait, timeout=5.0)
That said, this approach is hardly foolproof, and you may need to use other mechanisms depending on your particular case. The nice thing about async programming is that you don’t need to worry about being interrupted, so as long as you don’t await anything then you can always be assured your tasks will complete—I suggest that, wherever possible, you use this to make sure any required cleanup is performed.
As a closing comment, I’ll also note that as well as the close_clients() that we’ve seen, there’s also an abort_clients() which calls abort() instead of close(). This is similar, but closes connections more aggressively, not bothering to wait until any buffered data is sent.
There are a few changes which I didn’t feel required quite as much detail.
asyncio.loop.create_unix_server()cleanup_socket is True, which is the default. Looking at the code change, this correctly skips uses of the abstract namespace on Linux3.DatagramTransport.sendto()sendto() was called with an empty buffer, it would previously return immediately and do nothing. This made it impossible to send an empty datagram, which is sometimes required—for example, to implement the time protocol (RFC 868) As of Python 3.13 it will instead correctly send an empty datagram in this case.Queue.shutdownqueue.Queue object now supports a new shutdown() method and ShutDown exception. Similar changes have been made to the asyncio.Queue object as well. The shutdown() method has an immediate parameter, same as with the queue module, and the semantics are the same. The only real difference is that the exception is named QueueShutDown.Stream.readuntil()Stream.readuntil() has been available—we saw an example of its use in the code example in the Closing Server Connections section above. In Python 3.13 it now accepts a tuple of multiple separators, and will read until it encounters any of them.TaskGroup was nested inside another, an external cancellation could be masked by an internal task’s exception group handler, leaving the outer group missing its cancellation. At least I think that’s the case—honestly, it seems a bit of a niche case, and quite hard to fully grasp, but nonetheless good to see such issues being fixed. I didn’t drill in too far, but if you want to know the full details then go check out the original bug report and the pull request that fixes it.TaskGroupcreate_task() method is called on an inactive TaskGroup—that is to say one which isn’t yet been entered, is shutting down or has already finished—then you get a RuntimeError exception. However, the specified coroutine will still raise a RuntimeWarning about the coroutine never having been awaited, which is superfluous. As of Python 3.13, the coroutine will also have its close() method called immediately in these cases, which prevents the warning.mmap¶The mmap module has a few updates, the first of which is Windows-specific—this is a fix for an issue where the Python interpreter would crash if an inaccessible file was mapped.
The second change is that the mmap object has long had a seek() method, but it was missing the seekable() method from io.IOBase to indicate that it was, indeed, seekable. This has been added and always returns True. In addition the seek() method used to return None, but as of this release it returns the new absolute offset within the file, consistent with seek() methods on other file-like objects.
Finally, on Unix platforms (only), a new trackfd parameter has been added. This defaults to True, but if set to False then the input file descriptor will not be duplicated as part of the mapping process, and the mmap object will be linked with the same underlying file descriptor that was passed in. This is useful for limiting the number of open file descriptors your process has, to avoid hitting OS limits, but also means that the size() and resize() methods won’t work. In particular, resize() will raise a ValueError. In general, my suggestion isn’t to worry about this unless you’re likely to have hundreds of files open at once.
ssl¶A simple change in the ssl module—the create_default_context() has a couple of new flags added to the default set it uses for all purposes:
VERIFY_X509_PARTIAL_CHAINX509_V_FLAG_PARTIAL_CHAIN flag in OpenSSL, which causes all non-self-signed certificates in the trust store to be “trust anchors”—this means they are trusted to sign other certificates. This allows intermediate certificates in the trust chain to be stored and trusted to sign other certificates directly. Without this option, the trust store would need to include the ancestor root CA certificate. Many other implementations just behave like this by default without the need for flags, and indeed there have been discussions on removing the need for it from OpenSSL. So specifying it by default seems sensible and safe to me.VERIFY_X509_STRICTX509_V_FLAG_X509_STRICT flag in OpenSSL, which disables workarounds for broken certificates and strictly applies the X509 rules, as specified by RFC 5280.These are both sensible changes, in my view, and the first one should be quite safe. The second change, however, definitely has scope for breaking workflows that used to work, as there are still some certificates out there being generated in ways which don’t pass strict validation. For example, the basic constraints extension might be absent, which I believe is required for strict validation.
If the strict validation does break things, the correct long-term solution is, of course, to fix your certificates to be compliant with X.509 v3. However, this may be difficult or impossible in the short term, so you can disable the strict validation by just masking it out of the context flags after creation:
import ssl
ctx = ssl.create_default_context()
ctx.verify_flags &= ~ssl.VERIFY_X509_STRICT
A collection of smaller changes here. In summary:
base64 module now has functions for Z85 encoding and decoding.email has some additional header and address validation features.guess_file_type() in mimetypes to replace passing a filesystem path to guess_type().If that’s a little too brief for you, the following sections have some more details.
base64¶If you’re looking for something more compact than Base64 for encoding binary data as ASCII, there are a family of Ascii85 encodings you can use. The former uses four characters to represent three bytes of data, whereas the latter all use five characters to represent four bytes of data. Also, encoding data in groups of four bytes makes some implementation details a little easier to work with, as data often comes in multiples of four bytes.
Python’s base64 module already has the a85encode() and a85decode() functions for the standard Ascii85 encoding, and similar b85encode() and b85decode() functions for Base85 encoding4. The latter are used in diffs for binary objects in Git, by the way.
In addition to these there are other Ascii85 encodings. One of them is in RFC 1924, although I’d be careful about paying too much attention to this RFC—despite being referred to in the Ascii85 Wikipedia article, it was actually just an April Fools RFC. However, the character mapping it chose was used for Base85, so even humerous RFCs turn out to be useful sometimes, it would seem.
All of this is just introduction to the real change in Python 3.13, which is that there’s also z85encode() and z85decode() now added. These implement the Z85 encoding, which was created as part of the ØMQ5 specification.
This is essentially the same as b85encode() and b86decode() except with a different mapping of characters, and indeed the underlying implementation seems to be a call to those functions wrapped in a translation to the alterantive character set.
One thing that I found interesting was that these functions take a byte string of arbitrary length, because the standard clearly defines that the encoding must be done on a mutiple of 4 bytes, and that any padding required is the responsibility of the application.
In this case, however, it’s done by the Python implementation, because that functionality is provided by the underlying b85encode(). It appears to be done by just appending nul characters for the purposes of encoding, and then just removing as many characters from the end of the resultant string as padding bytes were added. This works fine as long as the encoding and decoder both use the same scheme, but I could see it causing issues if the Python implementation was used to encode, and some other scheme that didn’t support this padding was used to decode.
email¶A couple of changes in the email module for correctness and validation. First up, the email.generator module for serialising email objects to the string form required by SMTP agents now does better validation of headers. Previously it was possible to embed newlines in things like Subject headers, and this could allow someone who was able to maniupate the newline to inject additional headers, which could easily be used for malicious purposes.
Now, however, these are quoted on output to prevent literal newline characters from being passed through. Also, the email.generator module will refuse to write headers that don’t follow the correct folding and delimiting rules, as these might be interpreted as multiple different headers, or merged with adjacent headers.
If, for some weird reason, your code relies on this then you can disable this behaviour by setting verify_generated_headers in the email.policy.Policy object to False. However, I would strongly advise fixing the code instead—this sort of sloppiness is how security vulnerabilities creep in.
The second change is that email.utils.getaddresses() and email.utils.parseaddr() now return ('', '') (i.e. a failure to parse anything) in more cases where addresses don’t conform to RFC 5322 rules. Again, this sort of thing can create opportunities for malicious actors to abuse systems, so it’s important to be strict—to underscore that fact, this was actually highlighted in CVE-2023-27043.
>>> email.utils.parseaddr("someone@example.com <andy@andy-pearce.com>")
('', '')
It might be worth noting that these have also been backported to later releases of previous Python versions as well, as they are security updates, so even if you’re still on an older version, make sure you keep updated.
mimetypes¶Last up in this section, we have a new function guess_file_type() that’s been added to the mimetypes module. This is to supplement the existing guess_type() function, which guesses the MIME type of a file just from it’s filename based on a URL.
It’s always been possible to pass a local filesystem path to this function, and it’s still is, but that’s now soft-deprecated6. The replacement is the new guess_file_type() function, which does the same thing and has the same return values, but only works on filesystem paths. It still accepts the same strict parameter as guess_type(), which restricts the MIME types checked to those registered with IANA.
Why the change? Well, the fact that guess_type() parses URLs means that it has to deal with a lot of edge cases, and sometimes you can confuse it. So if you know what you have is a filesystem path, avoid all the ambiguities and complexity, and just use guess_file_type().
Admittedly I do struggle to come up with simple cases where they get confused, but you know that at some point someone’s going to name a directory http: and create a subdirectory called example.com, and create a file in that called page-??.html, and suddenly there’s a difference between the two7.
>>> mimetypes.guess_type("http:/example.com/page-??.html")
(None, None)
>>> mimetypes.guess_file_type("http:/example.com/page-??.html")
('text/html', None)
xml¶There are two changes in the xml module in this release. First up is a mitigation for vulnerability CVE-2023-52425 in the libexpat library, which is the XML parser included with Python, although other parsers may be used in some cases if available at runtime.
The vulnerability is that when parsing very large tokens, multiple fills of a smaller buffer are required within the library. If you maliciously send an extremely large token, this forces the token to be re-parsed from the start many times, which consumes a lot of CPU on the host.
To combat this, the Expat library introduced a mechanism called reparse deferral. This means that after parsing failures, it defers trying again until after a significant amount of new data arrives—this prevents an attacker dribbling in data in small quantities and forcing frequent expensive re-parses. The downside is that it may introduce more latency into the parsing, and lengthen the time to get feedback on parsing results.
If you know you can trust the data source and want to revert back to the old behaviour, there are two functions to access the API to do this in the underlying Expat library. These are both in xml.parsers.expat.xmlparser and consist of SetReparseDeferralEnabled() to set the mode, and GetReparseDeferralEnabled() to query the current state.
Additionally, if you’re using xml.etree.ElementTree and you want to trigger a reparse without fully disabling reparse deferral, you can call the flush() method that’s been added to XMLParser and XMLPullParser. This temporarily disables reparse deferral and triggers a reparse, leaving it back in its original state afterwards.
My suggestion would be to just leave it enabled unless you find in your actual real-world experience that these changes make any significant difference to your application.
The second change in this release is also in xml.etree.ElementTree, and a new close() method that’s been added to the object returned by the iterparse() function. This is part of a bug fix which ensures that the underlying filehandle, which is opened by iterparse() if you pass a filename, was not immediately closed. The new close() method isn’t typically required in CPython, because the issue was resolved another way8, but it remains in case it’s useful to explicitly close the underlying filehandle for any reason.
ipaddress¶A couple of changes in ipaddress. First is a new ipv6_mapped attribute on IPv4Address objects, which is an IPv6Address object representing the IPv4-mapped equivalent of the address—this is used during the transition to IPv6 to send IPv4 packets to IPv6 destinations. For more details see §2.5.5.2 of RFC 4291 and §4.2 of RFC 4038.
>>> import ipaddress
>>> ipaddress.IPv4Address("1.2.3.4").ipv6_mapped
IPv6Address('::ffff:1.2.3.4')
The other change is a fix to the logic which calculates the is_global and is_private attributes, which indicate whether the address is one of the globally reachable addresses as defined by the IANA registries for IPv4 and IPv6. Essentially there are some cases which were missing, but if you want to know specifics then check out the issue.
A couple of updates in doctest and a series of enhancements in doctest.
doctest, the output is now coloured by default.doctest, the DocTestRunner now counts skipped tests.typing, the addition of ReadOnly, TypeIs and NoDefault.typing.Protocol has had get_protocol_members() and is_protocol() methods added.doctest¶As we saw in an earlier article, the interpreter now supports coloured output. The first change in doctest is that output is also coloured by default. This does respect the usual PYTHON_COLORS, NO_COLOR and FORCE_COLOR variables, if you want to override the default.
As a quick example, here’s an excerpt from the output of running python -m pickle -v --test, which uses doctest.
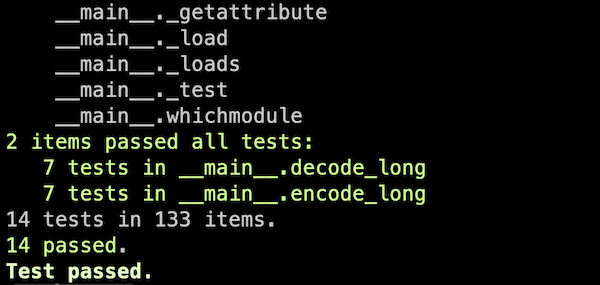
The second change is that DocTestRunner.run() now counts how many tests were skipped, as well as those that passed or failed. The DocTestRunner object has a new skips attribute which provides this count so far for the specified runner, and the TestResults object returned by the testmod() module function, and the run() and summarize() methods of DocTestRunner, has a skipped attribute which also makes this count available.
>>> import doctest, secrets
>>> doctest.testmod(secrets)
TestResults(failed=0, attempted=3, skipped=3)
typing¶Continuing the recent trend, there’s been some more active development on the typing module. Since there are a number of changes, I’ll break these out into subsections below.
ReadOnly¶Back in Python 3.8, a typing.TypedDict type was added to support heterogenous typed dictionaries, as I discussed in a previous article. This has always been a mutable type, however, and it’s been difficult to use it in cases where it should be regarded as an error if the value of a key is changed by a particular function.
This is where the new ReadOnly type modifier comes in—with it, you can mark any key as immutable. Of course, as with all type hinting, this won’t have any runtime effect, but should mean that type checks can detect violations of the restriction and raise warnings.
from datetime import datetime
from typing import ReadOnly, TypedDict
class FileEntry(TypedDict):
filename: str
last_update: datetime
creation: ReadOnly[datetime]
This can be mixed with the Required and NotRequired modifiers which were introduced in Python 3.11. See PEP 705 for more details about ReadOnly.
TypeIs¶In Python 3.10, the TypeGuard form was introduced, as we saw in a previous article. This allowed type hints to reflect runtime type checking that the code itself performed, e.g. using isinstance(), and allow the type checker to perform more accurate validations as a result.
from collections.abc import Iterable
from typing import TypeGuard
def is_iterable(x: object) -> TypeGuard[Iterable[Any]]:
return isinstance(x, Iterable)
This is useful, but has some limitations:
x if is_iterable() returns True—in particular, if it returns False, type checkers cannot infer x is not iterable, they can’t infer anything at all.x is Iterable[Any] if is_iterable() returns True—it cannot use any other information it may have about the value passed in, because the input and return types may be completely unrelated.PEP 742 has the useful example of isawaitable(), which I’ve adapted slightly below. Prior to this release, Typeshed annotated inspect.isawaitable() using TypeGuard. Consider running mypy on the example below9:
| awaitable.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
Since the only options available for t are Awaitable[int] or int, those are the two results we’d expect to see from the two reveal_type() calls. However, here’s what we actually get:
$ mypy awaitable.py
awaitable.py:10: note: Revealed type is "typing.Awaitable[Any]"
awaitable.py:12: note: Revealed type is "Union[typing.Awaitable[builtins.int], builtins.int]"
Success: no issues found in 1 source file
This illustrates the issues with TypeGuard preventing the type checking applying other information is has about t.
In Python 3.13, therefore, the new TypeIs form has been added with more helpful semantics in cases like this. It may only be used with type narrowing functions, which always return bool and always narrow the type of the first positional argument supplied. So something like this:
def type_narrower(x: BroadType) -> TypeIs[SpecificType]: ...
This indicates that type_narrower() is a function which takes an argument of type BroadType, and indicates whether x is actually of type SpecificType, which must be consistent with BroadType (that is to say, SpecificType could validly be used in a context where BroadType is expected).
This differs from TypeGuard in three ways:
TypeIs requires the narrowed type to be a subtype of the broad type, TypeGuard does not.TypeIs function returns True, type checkers can merge the result with other infomration they have to narrow the type more fully.TypeIs function returns False, type checks can exclude the specified type.Bearing all this in mind, let’s update our example above to use TypeIs instead of TypeGuard—here are just the section that’s modified:
| awaitable.py | |
|---|---|
3 4 5 6 | |
When we then re-run mypy, it illustrates that the stronger guarantees of TypeIs have allowed it to narrow down the types to be more specific:
$ mypy awaitable.py
awaitable.py:10: note: Revealed type is "typing.Awaitable[builtins.int]"
awaitable.py:12: note: Revealed type is "builtins.int"
Success: no issues found in 1 source file
If you want some more detailed discussion, PEP 742 has it.
As of this release, Python has three different flavours of type parameters for use with generics—the basic TypeVar was added in 3.5, ParamSpec for parameters was added in 3.10, and TypeVarTuple for variadic generics was added in 3.11. In this release we have the implementation of PEP 696, which adds type defaults to all three of these.
This simply means that if no type is specified for the type, it will be assumed to be the default one. This is perhaps best illustrated with an example, shamelessly adapated from one in the PEP:
| genericdefault.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
If we run mypy over this we can see that on line 10 where we’ve explicitly provided a value for value, the type shown is Container[int]. However, where we let value take its default None, the type defaults to str as specified in T, and so the type of the container is Container[str].
$ mypy genericdefault.py
genericdefault.py:10: note: Revealed type is "genericdefault.Container[builtins.int]"
genericdefault.py:11: note: Revealed type is "genericdefault.Container[builtins.str]"
Success: no issues found in 1 source file
As well as this behaviour, type variables have a new dunder attribute __default__ which specifies the default type. If there is no default, they use a new singleton typing.NoDefault for this attribute.
>>> from typing import TypeVar
>>> T1 = TypeVar("T1", default=int)
>>> T2 = TypeVar("T2")
>>> T1.__default__
<class 'int'>
>>> T2.__default__
typing.NoDefault
Protocol Changes¶There are a couple of small changes to typing.Protocol, the base class for protocols used for structural typing (also known as “static duck typing”), which was added in 3.8.
First up, there’s a new get_protocol_members() function which returns a set of the members in a specified protocol, or raises TypeError if the supplied type is not a protocol.
>>> from abc import abstractmethod
>>> from typing import Protocol, get_protocol_members
>>>
>>> class SupportsNameAndID(Protocol):
... name: str
... @abstractmethod
... def get_id(self) -> int:
... ...
...
>>> typing.get_protocol_members(SupportsNameAndID)
frozenset({'get_id', 'name'})
Second, there’s an is_protocol() function which returns True if and only if the specified type is a protocol.
ClassVar and Final¶The ClassVar annotation declares a variable as intended to be a class variable, and it shouldn’t be set on instances to hide it. Final indicates that a variable shouldn’t be reassigned—for example, it can be used for a constant which should not be updated, or a class variable which shouldn’t be updated or overridden in subclasses.
These two are somewhat similar, but have distinct purposes, but previously they couldn’t be used together. As of Python 3.13, however, they can.
Why would you want this? Well, let’s say you’re defining a dataclass and you want a constant that’s a class variable and shouldn’t be modified or overridden in any instance, now you can do it like this.
from dataclasses import dataclass
from typing import ClassVar, Final
@dataclass
class MyClass:
SOME_CONSTANT: Final[ClassVar[int]] = 123
...
pdb¶The pdb module has had a few updates. These are fairly small, so I’m just going to give a quick overview of them.
breakpoint() and set_trace() used to enter the debugger on the next line of code to be executed, but now they do so immediately to preserve the current context when a breakpoint is right at the end of a block.pdb changes sys.path[0] to the path of the current script, but as of Python 3.13 this isn’t done if the safe import path feature is enabled, which was added in 3.11 and can be enabled using the -P option or by setting the PYTHONSAFEPATH environment variable.zipapp supportzipapp module, for create of zip files containing Python code, is now supported by pdb as a debugging target.exceptions command in pdb to move between chained exceptions, when running a post-mortem debug of an exception using pdb.pm() when there’s an exception chain in scope. When run without arguments, it shows all the exceptions in the chain, and passing the number of one switches to that particular exception.>>> pdb.pm()
> <python-input-33>(7)<module>()
-> raise ThreeError("three")
(Pdb) exceptions
0 OneError('one')
1 TwoError('two')
> 2 ThreeError('three')
(Pdb) exceptions 0
> <python-input-33>(3)<module>()
-> raise OneError("one")
(Pdb) exceptions 1
> <python-input-33>(5)<module>()
-> raise TwoError("two")
A handful of changes in runtime services:
exc_type_str, and deprecate exc_type, on TracebackExceptionshow_group parameter to TracebackException.format_exception_only().@warnings.deprecated decorator to mark deprecations during type checking and runtime.traceback¶Two changes. First up concerns TracebackException, which is a snapshot of an exception which can be subsequently rendered. It’s intended to be lightweight, not preserving references, just enough information for a printable summary. The exc_type field stores the class of the original exception, but this was apparently causing issues in some cases by extending the lifetime of the class object. As a result this field is now deprecated, and a new exc_type_str should be used instead, which just stores the string name of the class.
The exc_type attribute can’t be removed at such short notice, but it’s deprecated, and code should migrate over to using exc_type_str. There’s a save_exc_type parameter to the TracebackException constructor, and also to the from_exception() method, to control whether exc_type is populated, so in cases where it causes problems it can already be turned off.
The second change is the addition of a new show_group keyword-only parameter to the format_exception_only() method of TracebackException. This parameter defaults to False, which preserves the old behaviour of just showing the specified Exception message. However, if you pass show_group=True and the exception is an instance of BaseExceptionGroup, then the output also includes the nested exceptions, with a correspondent level of indentation.
warnings¶As defined by PEP 702, there’s a new @warnings.deprecated decorator which can be used to mark a class or function as deprecated. This servces two functions: firstly, it allows static type checkers to warn about use of deprecated code; secondly, it may also generate a DeprecationWarning at runtime whenever it’s used.
This is an effort to make it easier for developers to detect when their code is relying on deprecated functionality—many people run with warnings disabled in production systems, and in pre-production testing not all code paths may be properly exercised, so deprecations may go undetected until they cause actual outages.
With this new decorator, static type checkers can be enlisted to generate these warnings, so pre-commit lint checks are much more likely to pick them up. As the PEP says, it may seem a slightly odd fit for type checkers to do this check, but it’s highly practical as they already do the sort of code scanning that is required, and are often already integrated into SDLC workflows.
The decorator takes a message as the first positional parameter, and this can be used to issue explanatory text for the user to briefly explain why the code is deprecated and suggest any alternatives. This message is saved in a __deprecated__ attribute added to decorated objects.
There’s a category parameter to specify the type of warning to raise at runtime, which rather sensibly defaults to DeprecationWarning, and you can set this to None to disable the runtime warning emission. For functions the warning is emitted at call time, for classes its on instantiation and on creation of subclasses. There’s also a stacklevel parameter to determine where the warning is emitted—the default of 1 emits in the direct caller, and higher values emit that many levels higher up the stack.
There are a few changes in the ast and dis modules. Since I suspect the audience for these changes is fairly small, I’ll try to be brief and maybe won’t provide as much context as I sometimes like to.
ast¶The ast module provides facilities for modelling abstract syntax trees, which are parsed versions of the Python grammar. The module provides object types to model all of the statements and expressions in the language.
The first change is that the constructors of the node types within ast (such as FunctionDef, ClassDef, AsyncFor) have been tightened up to check for required parameters, and emit DeprecationWarning if they’re not supplied—this will become a runtime exception in Python 3.15. Optional parameters that are omitted will have their attributes explicitly set to None.
The second change adds support for generating optimised syntax trees. Prior to 3.13, ast.parse() would always call with the underlying compile() builtin with optimisation disabled. In Python 3.13, however, there’s a new optimize parameter which, if passed a positive integer, passes the flag PyCF_OPTIMIZED_AST into compile() instead of PyCF_ONLY_AST for an unoptimised version.
The value of optimize is also passed to compile() to determine the level of optimisation—at time of writing 1 removes asserts and defines __debug__ to False, and 2 also removes docstrings.
dis¶You might imagine the dis module is for generating random insults, but actually it’s for disassembling Python byte code. A quick illustration is shown below.
>>> import dis
>>>
>>> def somefunc(a: int) -> int:
... print(f"I got an {a}")
... return a ** 2
...
>>> dis.dis(somefunc)
1 RESUME 0
2 LOAD_GLOBAL 1 (print + NULL)
LOAD_CONST 1 ('I got an ')
LOAD_FAST 0 (a)
FORMAT_SIMPLE
BUILD_STRING 2
CALL 1
POP_TOP
3 LOAD_FAST 0 (a)
LOAD_CONST 2 (2)
BINARY_OP 8 (**)
RETURN_VALUE
The first change is that disassemblies now show logical labels for jump targets instead of just showing the offset of each instruction, and just including the offset as the jump target. This makes things considerably easier to read. Take a look at the output below, and see how only the jump targets are annotated with labels L1 and L2.
>>> def anotherfunc(a: int) -> int:
... total = 0
... for i in range(10):
... total += a ** i
... return total
...
>>> dis.dis(anotherfunc)
1 RESUME 0
2 LOAD_CONST 1 (0)
STORE_FAST 1 (total)
3 LOAD_GLOBAL 1 (range + NULL)
LOAD_CONST 2 (10)
CALL 1
GET_ITER
L1: FOR_ITER 10 (to L2)
STORE_FAST 2 (i)
4 LOAD_FAST_LOAD_FAST 16 (total, a)
LOAD_FAST 2 (i)
BINARY_OP 8 (**)
BINARY_OP 13 (+=)
STORE_FAST 1 (total)
JUMP_BACKWARD 12 (to L1)
3 L2: END_FOR
POP_TOP
5 LOAD_FAST 1 (total)
RETURN_VALUE
If you still want the offsets back then you can pass show_offsets=True, but the new label IDs are still used.
>>> dis.dis(anotherfunc, show_offsets=True)
1 0 RESUME 0
2 2 LOAD_CONST 1 (0)
4 STORE_FAST 1 (total)
3 6 LOAD_GLOBAL 1 (range + NULL)
16 LOAD_CONST 2 (10)
18 CALL 1
26 GET_ITER
L1: 28 FOR_ITER 10 (to L2)
32 STORE_FAST 2 (i)
4 34 LOAD_FAST_LOAD_FAST 16 (total, a)
36 LOAD_FAST 2 (i)
38 BINARY_OP 8 (**)
42 BINARY_OP 13 (+=)
46 STORE_FAST 1 (total)
48 JUMP_BACKWARD 12 (to L1)
3 L2: 52 END_FOR
54 POP_TOP
5 56 LOAD_FAST 1 (total)
58 RETURN_VALUE
The second change is that the output of dis.get_instructions() has changed the presence of cache entries. As you might remember from a previous article, several of the functions in dis had a show_caches parameter to include the CACHE pseudo-instructions that were added by the specialising adaptive interpreter changes. The get_instructions() function, which returns an iterator of populated dis.Instruction instances for a piece of code, had such a parameter to control whether to include CACHE instructions.
In Python 3.13, however, this parameter is now ignored and separate CACHE instructions are never generated. Instead there’s a new cache_info attribute that’s been added in Python 3.13 and this is always populated. If there are no cache entries this is None, otherwise it’s set to a list of tuples of (name, size, data).
Here’s an excerpt from get_instructions() called in Python 3.12, with show_caches=True, showing a single LOAD_GLOBAL bytecode instruction and the associated CACHE pseudo-instructions after it.
Instruction(opname='LOAD_GLOBAL', opcode=116, arg=1, argval='range',
argrepr='NULL + range', offset=6, starts_line=3,
is_jump_target=False, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18))
Instruction(opname='CACHE', opcode=0, arg=0, argval=None,
argrepr='counter: 0', offset=8, starts_line=None,
is_jump_target=False, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18))
Instruction(opname='CACHE', opcode=0, arg=0, argval=None,
argrepr='index: 0', offset=10, starts_line=None,
is_jump_target=False, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18))
Instruction(opname='CACHE', opcode=0, arg=0, argval=None,
argrepr='module_keys_version: 0', offset=12,
starts_line=None, is_jump_target=False, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18))
Instruction(opname='CACHE', opcode=0, arg=0, argval=None,
argrepr='builtin_keys_version: 0', offset=14, starts_line=None,
is_jump_target=False, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18))
Now let’s compare this to the output for the same bytecode in Python 3.13—I think you’ll agree, this is actually a lot nicer. Note that this also illustrates some new attributes which were also added in 3.1310, but I’m not going to run through here.
Instruction(opname='LOAD_GLOBAL', opcode=91, arg=1, argval='range',
argrepr='range + NULL', offset=6, start_offset=6, starts_line=True,
line_number=3, label=None, positions=Positions(
lineno=3, end_lineno=3, col_offset=13, end_col_offset=18),
cache_info=[
('counter', 1, b'\x00\x00'),
('index', 1, b'\x00\x00'),
('module_keys_version', 1, b'\x00\x00'),
('builtin_keys_version', 1, b'\x00\x00')
])
Note that show_caches=True still has the same effect in dis.dis(), which still shows the pseudo-instructions.
We all love new toys11 and Python 3.13 has quite a haul of them—some may be modest, but still lovingly hand-crafted.
The focus on ability to deprecate things, both in argparse and with the warnings.deprecated decorator, is handle. Removing functionality always carries risk as you can’t necessarily rely on your users to read release notes or do sufficient testing, so the more ways we have of loudly flagging this to them in advance, the smoother life is for everyone.
The clean shutdown options in the queue module as well as in asyncio servers are also consistent with this general theme of making it easier to write well-behaved and reliable applications. It’s surprisingly common for developers to spend an awful lot of time worrying about how their applications behave whilst running correctly, and probably not enough time worrying about startup, shutdown and edge cases—any changes which make any of these easier to deal with are always welcome.
In terms of security, the changes to the default flags in ssl are good to see, even though I’m sure there will be a number of developers out there tearing their hair out as to why their Python applications suddenly start coughing up certificate errors after they upgrade their Python version. Let this be a lesson to make sure you understand X509 certificate validation at a general level before you start generating certificates.
It’s also nice to see typing get some love, although I do find myself becoming a little concerned that the type hint mechanism is now so complicated that it’s increasingly hard for less experienced developers to use it—or fully benefit from it, at the very least. This isn’t meant as a criticism of the core Python development team—I think it’s just an acknowledgement that making a language as flexible and introspective as Python type safe is an extremely challenging problem. Powerful, safe, easy: pick any two.
Well, that wraps up my coverage of Python 3.13, I hope it’s been of interest. The Python 3.14 release is locked to new features in early May, and its final release is due next October, so I’m sure there’ll be some more articles coming along in this series before too long.
For those who want the details, argparse has the facility to create complex parsers where a subcommand can have its own fairly detailed syntax of options or even its own subcommands. To support this, you can instantiate an ArgumentParser for the subcommand, and then add it to a parent. To add it, you call the add_subparsers() method on ArgumentParser to get a special object representing the subcommands, and then you can call add_parser() on it for each subcommand to create child ArgumentParser instance for that subcommand. So, the new deprecated parameter has been added to add_parser() to render an entire subcommand deprecated. ↩
Which, to be fair, is pretty easy to do. ↩
Briefly, by using a filename where the first character is NUL then the socket is created in the “abstract namespace” and not in the filesystem, and hence effectively vanishes when closed. This behaviour is Linux-specific, as far as I’m aware. ↩
What’s the difference? In short, they just map each byte to a different character. Ascii85 maps characters direct to their ASCII value minus 33—this makes it a little easier to implement, but means it contains characters such as " which are annoying to have to include in string literals and the like. Base85, on the other hand, uses a more carefully chosen subset of ASCII which is slightly fiddlier to map to bytes, but avoids inconvenient characters. ↩
ØMQ (pronounced “zero MQ”) is a C++ library for asyncronous network communication, with bindings in several langauges. Unlike many other messaging middleware, it doesn’t itself supply a broker, but rather adds facilities to exiting basic network sockets such as queuing and broadcast across multiple subscribers. It’s more work to use than an out-of-the-box broker-based middleware—but it offers more flexibility, and provides robust and tested solutions to a number of problems you’d probably need to solve yourself if you built directly on top of TCP/UDP sockets. ↩
When something is soft-deprecated, its use is discouraged and there won’t be further development of it, but there are no plans to schedule its removal either. ↩
You may say that could never happen, but just be aware that sort of thinking is how a decent proportion of production outages start… ↩
I believe the issue was a reference cycle that was fixed by using weakref, and hence the filehandle gets cleaned up promptly. ↩
The reason why I’ve wrapped inspect.isawaitable() with my own my_isawaitable() function is simply to insulate this example from the type hinting of that function, since in Python 3.13 it’s been updated to resolve this issue with the TypeIs form that we’ll see in a moment. ↩
Just to save you comparing, the other new attributes of dis.Instruction in Python 3.13 aside from cache_info are start_offset, cache_offset, end_offset, baseopname, baseopcode, jump_target, oparg, and line_number. ↩
toy, n.: feature or tool for software development which is useful, clever, or just a bit cool even though you sadly doubt that you’ll ever have a real-world use for it. ↩